
About
이번 블로그에서는 최근(12월 3일)에 Netflix에서 발표한 Metaflow library에 대해서 간단히 공부한 내용을 소개하고자 한다. 기본 개념은 이해하고 있고 간단한 코드 및 문법을 알고싶다면 다음 블로그으로 바로 이동하면 된다.
Metaflow 란?
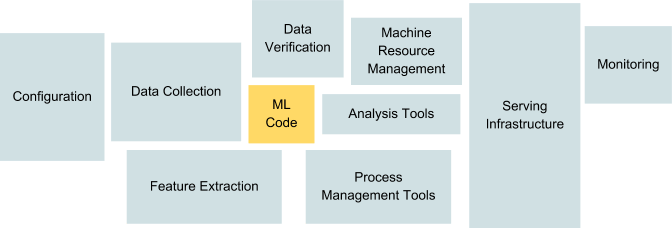
위의 이미지는 Google의 유명한 논문에서 소개된 것이다. Machine Learning 코드가 시스템에서 작동되기 위해서 필요한 인프라의 비중을 보여주는 것이다.
Metaflow는 바로 Netflix가 위와 같은 복잡한 시스템에서 인프라와 머신러닝 모델간의 효율적인 협력이 가능하도록 고민하여 만든 결과물이다. Netflix tech blog에 따르면 당시에 새로운 Machine Learning Infrastructure 팀이 구성되면서 조사를 했다고 한다.
회사의 Data scientist에게 가장 힘든 점이 무엇인지 물어본 결과는 빅데이터와 모델링에 대한 이야기일 것이라는 예상과는 전혀 달랐다. 그들의 답은 첫 모델이 나온 후로 프로덕션에서 사용되기까지 너무 오랜 시간이 걸리며, 데이터 접근과 기본적인 데이터 처리가 가장 힘들다는 것 이었다. 그래서 Netflix 팀은 아래와 같은 표를 정리하게 된 것이다.

그들은 “인프라 팀은 Data scientist가 software 구조에는 걱정없이 자유롭게 연구할 수 있게 돕는 동시에 적절한 가드레일을 제공해야한다.”는 목표로 위의 표에서 하단에 해당하는 작업들은 좀 더 규범을 중시하도록 구성하고 상단의 작업들은 Data scientist들이 평소 사용하던 PyTorch, Tensorfow와 같은 라이브러리들을 자유롭게 사용할 수 있도록 유연성있게 만들었다.
The infrastructure should allow them to exercise their freedom as data scientists but it should provide enough guardrails and scaffolding, so they don’t have to worry about software architecture too much.
위 이미지는 간단한 예제를 보여주고 있다. 각 step들은 function으로 이뤄져있는 것을 확인할 수 있고 아래와 같은 절차로 진행된다.
- start : 모델링에 사용할 data를 불러온다.
- fitA, fitB : 병렬적으로 서로 다른 모델을 학습한다.
- eval : fitA, fitB의 학습이 끝나면 각 모델의 결과를 확인하여 더 높은 모델을 선택한다.
-
end : 그래프의 마지막은 항상 end라고 이름지어야 한다.
뭔가 깔끔해보이긴 하지만 예제만으로는 기존의 Framework나 Library들과 어떻게 다른 것인지 감이 오질 않는다. Y Combinator의 The hacker news에서도 같은 질문을 하는 사람이 있었다.
“완전히 이해하기전에 비판하고 싶지는 않지만, 소개된 Tutorial만 봐서는 내가 R이나 Python으로 구현할 수 있는 것과 달라보이는 것이 없다. 메인 Feature를 알려달라.”
그러자 Metaflow team은 아래처럼 답했다.
- Metaflow는 당신의 코드, 데이터와 의존성들을 자동으로 저장한다(보통은 S3와 연결해서 사용한다). 이로인해 과거의 결과를 재생산 가능하고, workflow 상의 뭐든지 자세한 확인이 가능하다. 이 것이 Metaflow의 핵심 기능이라 할 수 있다.
- Metaflow는 클라우드 벡엔드와 잘 협력할 수 있도록 기획되었다. 우리는 AWS와의 호환을 적극 지원한다(다른 클라우드도 가능하다). 이 부분에 특히 많은 엔지니어링이 들어갔는데 예를들어 Metaflow에서 제공하는 S3 client 모듈을 이용하면 10Gbps 속도로 데이터를 가져올 수 있는데 이는 AWS CLI를 이용하는 것 보다 빠르다.
- 우리는 많은 시간과 노력을 할애하여 API 부분의 코드가 최대한 깔끔하게 유지되고 사용되기 쉽게끔 하였다. 회사 상황마다 다르겠으나 현재까지 우리 내부 사용자들은 매우 만족해하고 있는 부분이다.
아직 프로덕션 환경에 적용해보지 않은 필자로써는(할지 안할지도 아직 모르긴 함..) 마지막 3번째 답변이 가장 와닿는다.
이 외에도 Netflix tech blog에서는 아래처럼 설명했다.
Metaflow는 Python의 한계를 넓혔다. 병렬화와 최적화를 통해서 Python 코드로 10Gbps의 속도로 데이터를 가져올 수 있게 하였고, 메모리상 수천만 포인트의 데이터를 핸들링한다. 또한 수천개의 CPU코어들을 오케스트레이션하여 계산하게 만들었다.
Metaflow code의 구조
Metflow는 the dataflow paradigm을 따라 연산이 연결된 그래프의 형식이다.
from metaflow import FlowSpec, step
class HelloFlow(FlowSpec):
@step
def start(self):
print("HelloFlow is starting.")
self.next(self.hello)
@step
def hello(self):
print("Metaflow says: Hi!")
self.next(self.end)
@step
def end(self):
print("HelloFlow is all done.")
if __name__ == '__main__':
HelloFlow() 간단하게 각 연산(함수)들은 @step 데코레이션을 사용하여 선언된다. 위의 예는 가장 기본이 되는 코드인데 위에서 설명한대로 코드는 깔끔하고 각 step별로 체계적인 관리가 가능해보인다.
반드시 따라야하는 기본 구조는 start, end라는 이름의 함수들이 있어야 한다는 것이다. 기능은 이름과 같다. 가장 먼저 실행되는 함수는 start, 끝은 end라고 해야하며 그 사이는 자유롭게 이용하면 된다.
Conclusion
여기에 기본 코드 및 문법을 설명하게되면 너무 길어질 것 같으므로 다음 블로그에서 기본 코드 및 문법에 대해서 소개하도록 하겠다.

