이번 포스트에서는 Tensorflow에서 꼭 알아야 할 기본적인 지식들에 대해서 알아보자.(Tensorflow설치법에 대해서는 다루지 않을 것)
1. Dataflow
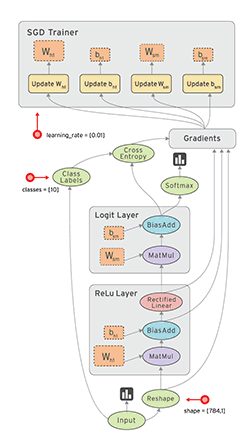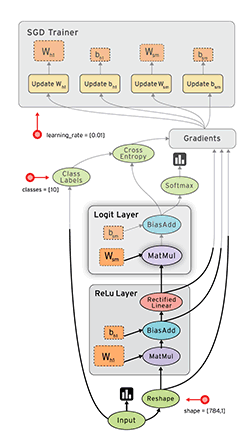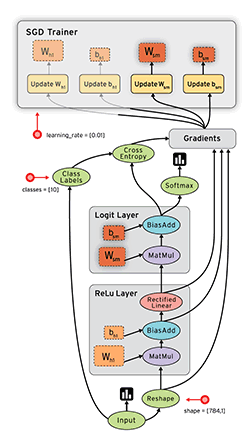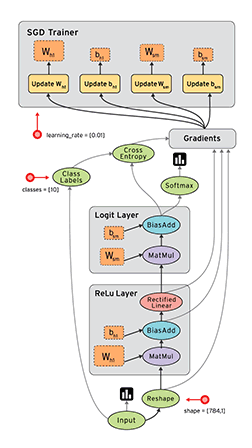
옆의 그림은 Tensorflow 공식 홈페이지에 나와있는데, 정말 직관적으로 Tensorflow의 Dataflow Graph(Node And Operation) 를 표현해냈다.
먼저 Tensor 는 옆에서 보이는 검은 라인이고(Edge), Operation 은 노드(Node)들, 그림에서 타원들을 의미한다. 즉, Tensor가 Operation으로 들어가서 해당 Operation에서 설정한 연산을 진행하고 다시 Tensor를 Output으로 내보내는 것이다.
필자가 이해한 바대로라면 Tensor나 Operation이라는 낯선 단어들을 사용해서 어렵게 느껴지지만 결국은 함수의 기능을 한다고 봐주면 되겠다. 차이점은 Graph는 선언이고 Session을 통해서 Run을 한다는 것
물론! 끝은 Output으로 값을 내보내는 것을 목적으로 하는 것은 아니다. 우리의 목적은 W 가중치 를 Update 하는 것이므로, 마지막에 우리가 Optimizer 의 변수로 설정한 W1, b1, W2, b2 ... 들이 Update 되는 것으로 Session.run() 이 종료된다.
import tensorflow as tf
sess = tf.Session()
sess.run(task)
sess.close()2. Operation의 name과 scope의 간략한 소개
본격적으로 코드에 대해 설명하기 전에 Debugging 에 도움이 되는 정보인 Operation name에 대해서 간략하게 살펴만 보자.c_0 = tf.constant(0, name="c") # => operation 이름은 "c"
# 이미 사용된 이름은 자동으로 유니크화 시킨다.
c_1 = tf.constant(2, name="c") # => operation 이름은 "c_1"
# Name scope는 접두사로 붙게되는데 나중에 설명할 Tensorboard에서 확인할 때 훨씬 편리하다.
with tf.name_scope("outer"):
c_2 = tf.constant(2, name="c") # => operation 이름은 "outer/c"
# Name scope 아래로는 경로로 계층을 표현한다.
with tf.name_scope("inner"):
c_3 = tf.constant(3, name="c") # => operation 이름은 "outer/inner/c"
c_4 = tf.constant(4, name="c") # => operation 이름은 "outer/c_1"
with tf.name_scope("inner"):
c_5 = tf.constant(5, name="c") # => operation 이름은 "outer/inner_1/c"3. Tensorflow 가장 많이 사용되는 함수들을 알아보자
이 포스트에서는 필자가 많이 사용된다고 생각하는 가장 기본적인 함수들만 작성했는데, 이 외에도 거의 모든 수학 연산은 다 구현되어 있으니 자세한 API는 링크를 통해서 찾아보도록 하자.tf.placeholder()
tf.placeholder( dtype, shape=None, name=None )tf.placeholder() 는 머신러닝에서 무조건 사용하는 함수이며, 구조는 위의 코드에서 보듯 dtype, shape, name으로 이루어져있는데 핵심은 shape 이다.
다른 포스트에서 언급하겠지만 tensorflow에서 shape을 이해하는 것은 매우 중요하다.
예를 들어 집값을 예측하는 모델을 우리가 만들고 있고, 집의 Feature(특징) 는 rooms, is_riverside 로 이루어져 있다고 하자. 그리고 만약 우리가 최종적으로 사용할 Feature 의 수는 위에서 말한 두 가지면 충분하다고 결정했다고 본다면, Input 데이터의 shape 으로 [?, 2], 즉 컬럼은 2 개로 결정을 한 상태라는 것이다. 하지만, 집의 개수, 즉 데이터의 개수는 많을수록 좋은 것이므로 변동의 여지가 언제나 있는 값일 뿐 아니라 최종적으로 우리가 새로운 데이터를 예측하려 할 때에도 변하는 값이라는 것이다.
그런 이유에서 tensorflow 에서는 placeholder 라는 함수를 제공하는 것이며, Feature(X) 와 Label(y) 은 placeholder 를 사용해서 넣어준다. 주의할 점은 sess.run() 시에 feed_dict 에 꼭 값을 직접 넣어(feed) 주어야 한다는 것.import tensorflow as tf x_data = np.array([[3, 1], [4, 0], [5, 1]]) y_data = np.array([[120000], [100000], [200000]]) X = tf.placeholder(tf.float32, shape=[None, 2], name="X") # 이 예제에서는 각 집마다의 가격을 예측하는 것이므로, shape은 [None, 1]이 된 것. y = tf.placeholder(tf.float32, shape=[None, 1], name="y")tf.Variable()
`python tf.Variable(, name= ) ` 머신러닝을 통해서 구하고자하는 값인 Weight 나 Bias 와 같은 값은 tensorflow 의 tf.Variable() 함수를 사용해서 선언해야한다. 구조는 위의 code에서 보듯 아주 단순하며, 보통은 Random하게 초기화하는 경우가 많으므로 행렬곱을 할 상대인 X 와 예측 값으로 내보내는 y 의 shape 을 고려해서 tf.random_normal() 을 사용하게 된다. W = tf.Variable(tf.random_normal([2, 1]), name='wight') b = tf.Variable(tf.random_normal([1]), name='bias')tf.matmul()
tf.matmul( a, b, transpose_a=False, transpose_b=False, adjoint_a=False, adjoint_b=False, a_is_sparse=False, b_is_sparse=False, name=None )머신러닝에서는 원소간의 곱(Element-wise multiplication) 보다는 행렬곱(Matrix multiplication) 이 훨씬 많이 쓰이므로 tf.matmul() 은 꼭 알아야하는 함수이다.
hypothesis = tf.matmul(X, W) + btf.train module
오늘 소개할 마지막은 함수가 아닌 모듈(Module) 이다. 아래는 가장 보편적인 Optimizer 인 GradientDescentOptimizer 로 예를 들었지만, 훨씬 많은 모델들을 tensorflow 에서는 제공하고 있으니, 이 외에 필요한 정보는 링크에서 확인하도록 하자.
목표 함수(Cost function) 에 대해서 이 포스트에서는 특별히 다루지 않지만, 다음 포스트들에서 CNN, RNN 등의 알고리즘을 구현하며 설명을 추가하겠다.
cost = tf.reduce_mean(tf.square(hypothesis - y)) train = tf.train.GradientDescentOptimizer(learning_rate=lr).minimize(cost)
4. 마무리
이번 포스트는 어려운 내용이 없지만 tensorflow 를 공부하며 간단한 모델들을 구현해보며 가장 자주 사용되고 중요하다고 느꼈던 점을 정리해보았는데, 처음 시작하는 사람들에게 꼭 도움이 되길 바란다.
아래는 가장 간단하게 회귀분석 모델을 구현한 코드이며, 위에서 설명한 개념들을 정말 간단한 예제이긴 하지만, 대략적으로 어떻게 쓰이나 보여주기 위해서 작성해보았다.
import tensorflow as tf
x_data = np.array([[3, 1], [4, 0], [5, 1]])
y_data = np.array([[120000], [100000], [200000]])
# hyper parameter
lr = 0.01
n_epoch = 2000
X = tf.placeholder(tf.float32, shape=[None, 2], name="X")
y = tf.placeholder(tf.float32, shape=[None, 1], name="y")
W = tf.Variable(tf.random_normal([2, 1]), name='wight')
b = tf.Variable(tf.random_normal([1]), name='bias')
hypothesis = tf.matmul(X, W) + b
cost = tf.reduce_mean(tf.square(hypothesis - y))
train = tf.train.GradientDescentOptimizer(learning_rate=lr).minimize(cost)
with tf.Session() as sess:
# 변수가 있는 경우에는 초기화를 실행해줘야 한다.
sess.run(tf.global_variables_initializer())
# train이 반환하는 값은 우리에게 필요없다.
for step in range(n_epoch):
c, _ = sess.run([cost, train], feed_dict={X: x_data, y: y_data})
if step % 500 == 0:
print("Step :", step, "Cost :", c)
# x, y를 임의로 만든거라..
# 이 부분은 train data를 학습시키는지 확인하는 목적 외에는 없다.
print(sess.run(hypothesis, feed_dict={X: x_data}))
